AI Agents Don't Need Meetings: Gotanda Style for Stigmergic Software Maintenance

Most multi-agent systems make agents talk to each other.
We tried something different: our agents do not talk to each other at all.
They leave traces in a shared environment. Other agents read those traces later, combine them with new evidence, turn the right ones into GitHub issues, and sometimes produce pull requests.
This pattern is called stigmergy: coordination through changes left in the environment rather than direct communication between individuals. In this article, I will call our version of the pattern Gotanda Style.
This is not just a thought experiment. We already use this workflow to maintain a Python repository with roughly 200,000 lines of code. Sentry alerts deposit "pheromones." Aggregated signals become issues. Some of those issues are small and well-scoped enough for an implementation agent to turn into pull requests.
The result is a multi-agent maintenance loop that is asynchronous, leaderless, token-efficient, and built for real software operations rather than demo-friendly agent conversations.
TL;DR
Faster coding agents increase maintenance pressure: production errors, performance regressions, test gaps, and architectural drift all grow with change velocity.
Gotanda Style coordinates agents through a shared pheromone field instead of direct agent-to-agent conversation.
Observer agents deposit structured positive and negative signals; an integrator turns only the right clusters of evidence into issues.
This lets maintenance agents run asynchronously, spend fewer tokens, avoid supervisor bottlenecks, and route only safe, well-scoped work to implementation agents.
Why maintenance matters more as coding agents get better
AI coding agents are making it much faster to write code.
That is a real shift. But when code creation gets faster, the maintenance burden grows too. More code reaches production in less time. More changes need monitoring, debugging, refactoring, testing, and design review.
It is like doubling the speed of a car. Higher speed is useful, but only if the tires, brakes, suspension, and safety systems can handle it. Otherwise, speed just turns small failures into bigger ones.
In AI-assisted development, speeding up implementation is not enough. The maintenance system has to scale with the new velocity.
Software work is not just "writing code." Over the long run, a large share of the cost comes from work like this:
Investigating production errors
Detecting performance regressions
Filling test gaps
Finding architectural drift
Repairing broken boundaries between modules
Converting small improvement opportunities into reviewable pull requests
The faster AI helps us produce code, the more important these loops become.
If we want AI-driven development to scale, we need more than automated code generation. We need agentic maintenance.
Gotanda Style came from that problem. The goal is not to hand all product or architecture decisions to AI. The goal is to use multiple agents to continuously support the parts of software maintenance that are repetitive, observable, and evidence-driven.
Why conversational multi-agent systems are hard to scale
When people hear "multi-agent system," they often imagine a group of specialist agents solving a problem by talking to each other.
A typical setup looks like this:
A planner agent decomposes the task
A research agent investigates context
A coding agent implements the change
A reviewer agent reviews the result
A supervisor agent decides what happens next
This can work well for small tasks. Many current agent frameworks are built around patterns like supervisors, handoffs, routers, and subagents.
But software maintenance is different. It is continuous, asynchronous, broad in scope, and tied to production evidence. For that kind of work, conversation-centered coordination has several problems:
As the number of agents grows, the communication graph gets harder to manage.
Agents need to read each other's context, which increases token usage.
The supervisor becomes an information bottleneck and a potential single point of failure.
In a large codebase, having every agent read the same context is wasteful.
Temporary opinions and noisy reasoning can stay in the chat history and bias later decisions.
Human organizations have the same failure mode. A team that keeps everyone in every meeting slows down as it grows.
The same thing happens with LLM agents. After a certain point, coordination itself becomes the cost.
Gotanda Style: coordinate through the environment, not through chat
The core rule of Gotanda Style is simple:
Agents do not talk to each other. They leave traces in a shared environment.
Each agent observes only its own slice of the system. When it finds a signal, it writes that signal into a shared environment.
We call that shared environment the pheromone field.
For example:
Sentry worker: observes runtime errors
Datadog worker: observes slow requests, slow SQL, 5xx spikes, and cost spikes
Quality worker: looks for layering violations, missing exception handling, test gaps, and API contract drift
Refactor worker: reads the pheromone field, combines related signals, and creates issues
Code worker: picks up Gotanda-labeled issues and opens pull requests
The important part is that observer workers do not directly create a flood of GitHub issues.
The Sentry worker leaves a trace that says, in effect, "this file is involved in a production error." The Datadog worker leaves a trace that says, "this endpoint is slow." The Quality worker leaves a trace that says, "this function may have an error-handling problem."
They do not negotiate with each other in chat.
Later, the Refactor worker reads the accumulated pheromone field and decides which clusters of evidence are worth turning into issues.
The workflow has three stages:
Observer: observes the outside world or the codebase and deposits pheromones
Integrator: reads the pheromone field, merges related signals, and creates issues
Implementer: turns safe, well-scoped issues into pull requests
Sentry worker ----+
Datadog worker ----+--> Pheromone field --> Refactor worker --> GitHub Issue --> Code worker --> Pull Request
Quality worker ----+
What is a pheromone?
A pheromone is a structured signal that an agent leaves in the shared environment.
A minimal model looks like this:
(scope, location, worker, strength, half_life, metadata)
Each field has a specific role:
scope: the granularity of the signal, such asfile,function,endpoint, orsqllocation: the actual target, such as a file path, function name, API route, or SQL fingerprintworker: the agent that deposited the signalstrength: how strong the signal ishalf_life: how quickly the signal decaysmetadata: supporting details such as error category, environment, evidence, or classification
If the Sentry worker finds a production error, it might deposit a pheromone like this:
{
"scope": "file",
"location": "app/services/invoices.py",
"worker": "sentry-worker",
"strength": 2.0,
"half_life_days": 14,
"metadata": {
"category": "runtime_error",
"environment": "production",
"error_type": "IntegrityError"
}
}
If the Quality worker finds a test gap in the same file, it might deposit a separate pheromone:
{
"scope": "file",
"location": "app/services/invoices.py",
"worker": "quality-worker",
"strength": 1.0,
"half_life_days": 21,
"metadata": {
"category": "test_gap",
"severity": "medium"
}
}
The Refactor worker does not make decisions from a single deposit in isolation. It reads the aggregated field.
When multiple workers deposit signals around the same location, that location becomes a hotspot worth inspecting.
Positive and negative pheromones
In Gotanda Style, pheromones are not always positive.
A positive pheromone is an attraction signal: "look here."
A negative pheromone is an inhibition signal: "we looked at this, and for now we should not pursue it."
For example, if the Refactor worker investigates a candidate and decides that it is an accepted design exception, it can deposit a negative pheromone:
{
"scope": "fingerprint",
"location": "layering_violation:abc123",
"worker": "refactor-worker",
"strength": -1.5,
"half_life_days": 60,
"metadata": {
"reason": "accepted design exception"
}
}
This prevents the same candidate from becoming a new issue every time a worker sees it.
But the negative pheromone is not permanent. It decays over time. If Sentry or Datadog later deposits a strong signal in the same area, the candidate can resurface.
That property matters in maintenance work. "Won't fix right now" is not the same thing as "ignore forever."
Why this scales
1. More agents do not create a communication explosion
In a conversational design, every new agent raises a coordination question: who needs to talk to whom, when, and with how much context?
In Gotanda Style, agents do not need to know about each other. They only need to write signals into the shared environment using a known schema.
Adding a new worker is mostly a contract question: what kind of pheromone does it deposit?
That makes the system plugin-like. If you want a Security worker, it deposits security signals. If you want a Performance worker, it deposits performance signals. The Refactor worker can read both as part of the same field.
2. Large codebases can be explored more efficiently
In a large codebase, reading every file on every run is not realistic.
The real question is how to spend a limited exploration budget.
With a pheromone field, exploration is not purely random, and it is not limited to "recently changed files" either. A worker can prioritize:
Recently changed files
A random sample of files
Hotspots from Sentry or Datadog
Areas with strong negative pheromones, at a lower priority
Locations where multiple workers have deposited signals
The search budget adapts to observed evidence.
That is a good fit for continuous AI maintenance over a large codebase.
3. It is token-efficient
Because agents do not have long conversations with each other, they do not need to read each other's full reasoning traces or chat histories.
What gets shared is a small structured signal:
{
"scope": "endpoint",
"location": "GET /api/reports",
"worker": "datadog-worker",
"strength": 1.2,
"metadata": {
"category": "slow_request",
"p95_ms": 1800
}
}
That is far cheaper than thousands of tokens of conversation.
Only when the Integrator needs to make a decision does it dig into the code, logs, issues, and previous decisions.
4. It runs asynchronously
Workers do not need to run at the same time.
The Sentry worker can run every 10 minutes. The Datadog worker can run once a day. The Quality worker can run overnight. The Code worker can poll for labeled issues every few minutes.
Each worker observes the environment and deposits pheromones at its own pace.
That is useful in production. External systems like GitHub, CI, Sentry, and Datadog all have different rate limits, failure modes, and latency profiles. Independent workers localize failures instead of turning every dependency hiccup into a global coordination problem.
5. Noise can be handled over time
LLM agents are noisy. A weak signal from one worker should not always become an issue.
In Gotanda Style, pheromones decay.
A one-off weak signal fades away. Signals that recur, signals that come from multiple workers, and signals tied to production impact remain stronger.
This helps the system prioritize persistent problems over one-time noise.
A simple sum is not enough
There is an important catch.
If you simply add pheromones together, you can lose information.
Imagine a location has these two signals:
sentry-worker: +2.0
refactor-worker: -2.0
The simple sum is zero.
But this is not the same as a location where nothing is happening.
It means something closer to: "there is a production error here, but there is also a previous won't-fix decision."
If we treat both cases as zero, we miss an important conflict.
So Gotanda Style tracks positive mass, negative mass, total variation, and conflict separately:
current_strength: net strengthpositive_strength: total positive signalnegative_mass: total negative signaltotal_variation: total signal without cancellationconflict_ratio: how strongly positive and negative signals disagree
The practical rule is simple:
Distinguish silence from conflict.
This lets the Refactor worker make better decisions:
Strong positive signal only: possibly safe to turn into an implementation issue
Strong negative signal only: do not pursue right now
Strong positive and negative conflict: likely needs human review
No signal: lower exploration priority
How issues are created in Gotanda Style
Observer workers generally should not create issues directly.
They usually do not have enough context at observation time.
The Sentry worker knows about an error, but it may not know whether the fix is local, architectural, already accepted, or intentionally deferred.
The Datadog worker knows about a slow SQL query, but it may not know whether the query is unacceptable, part of a tolerated batch job, or tied to a product requirement.
The Quality worker may find something that looks like a layering violation, but it may be an intentional design exception.
So observer workers deposit pheromones. Issue creation belongs to the Integrator.
The Integrator reads multiple pheromones, the current code, existing issues, and previous won't-fix decisions. Then it classifies the candidate:
| Class | Meaning | Destination |
|---|---|---|
| A | No issue, or known accepted exception | Do not file |
| B1 | Safe local fix | Code worker |
| B2 | Design decision needed | Human |
| C | Cause unclear; investigation needed | Human |
Only B1 goes to the Code worker.
That boundary is intentional. Issues sent to an implementation agent should have a clear intent, a limited scope, and enough evidence that a reviewer can trace the pull request back to the original problem.
Large design decisions stay with humans. Once a human decides the direction, the local follow-up work can be split into smaller issues for the Code worker.
What is already working
Gotanda Style is not just a research sketch.
We are using this pattern on a Python repository with about 200,000 lines of code.
The current loop works like this:
The Sentry worker detects a production alert.
It classifies the alert and deposits pheromones for cases that appear to need either a local fix or deeper remediation.
The Refactor worker reads the pheromone field and combines the alert with other observations and previous decisions.
It creates improvement issues at a level of detail that can be implemented automatically.
The Code worker reads the issue, creates a branch, makes the change, and opens a pull request.
Not every alert becomes an automated fix. Anything that needs a design decision, has an unclear cause, or has a large blast radius is routed to a human.
But the closed loop from Sentry alert to pheromone deposit to issue to improvement PR is already running in practice.
That is the key point: Gotanda Style did not come from abstract multi-agent theory. It came from operating and maintaining a real large codebase.
What is new here?
Multi-agent systems are not new.
There are many existing patterns: supervisors, handoffs, routers, blackboards, shared memory, and more.
The interesting part of Gotanda Style is the combination:
It is specialized for software maintenance.
It separates observation, integration, and implementation.
Agents do not talk to each other directly.
Agents deposit positive and negative pheromones into a shared environment.
Pheromones decay over time.
Hotspots and conflicts across observers drive issue creation.
Only safe, automatable issues are passed to the Code worker.
This is not a general-purpose chatty multi-agent system.
It is an asynchronous, leaderless, token-efficient workflow pattern for continuously maintaining a large codebase.
The hard parts
This pattern has real challenges.
The biggest one is the quality of the pheromone field.
If the field fills with noise, the whole system follows that noise. If inhibition is too strong, the system misses real problems.
Several parts are especially tricky.
Normalizing locations
If workers refer to the same place using different location strings, signals will not aggregate.
For example, these may all refer to the same API:
GET /api/users/{id}
/api/users/:id
app/api/users.py:get_user
Deciding when these should collapse into one location is an important design problem.
Calibrating strength
A Sentry production error with strength +2.0 should not carry the same meaning as a low-confidence Quality worker concern with strength +0.5.
The system needs ongoing calibration across worker reliability, category severity, environment, and production impact.
Defining negative pheromone semantics
Negative pheromones are useful, but they are also dangerous.
"Do not pursue right now" is different from "ignore forever."
Negative pheromones need reasons, fingerprints, half-lives, and resurfacing conditions.
Auditability
As automation increases, the system has to explain itself.
Operators need to trace why an issue was created, why a pull request was opened, which worker run contributed which signal, and which previous decisions were considered.
Without that audit trail, the workflow will not be trusted in production.
What we want to improve next
Gotanda Style is still evolving.
The next areas we care about most are:
Reliability weights per worker
Category-specific weights
Location alias normalization
Audit logs tied to
run_idSelf-stop conditions
Canary operation
Human-in-the-loop boundaries
Reallocating exploration based on the pheromone field
The last point is especially important. The field should not only be something agents read when making issues. It should also shape what agents inspect next.
For example, instead of letting the Quality worker explore completely at random, it can divide its budget like this:
Recent files: 40%
Random files: 30%
Pheromone hotspots: 20%
Cooling follow-up: 10%
This keeps some randomness while adapting to what the system has already observed.
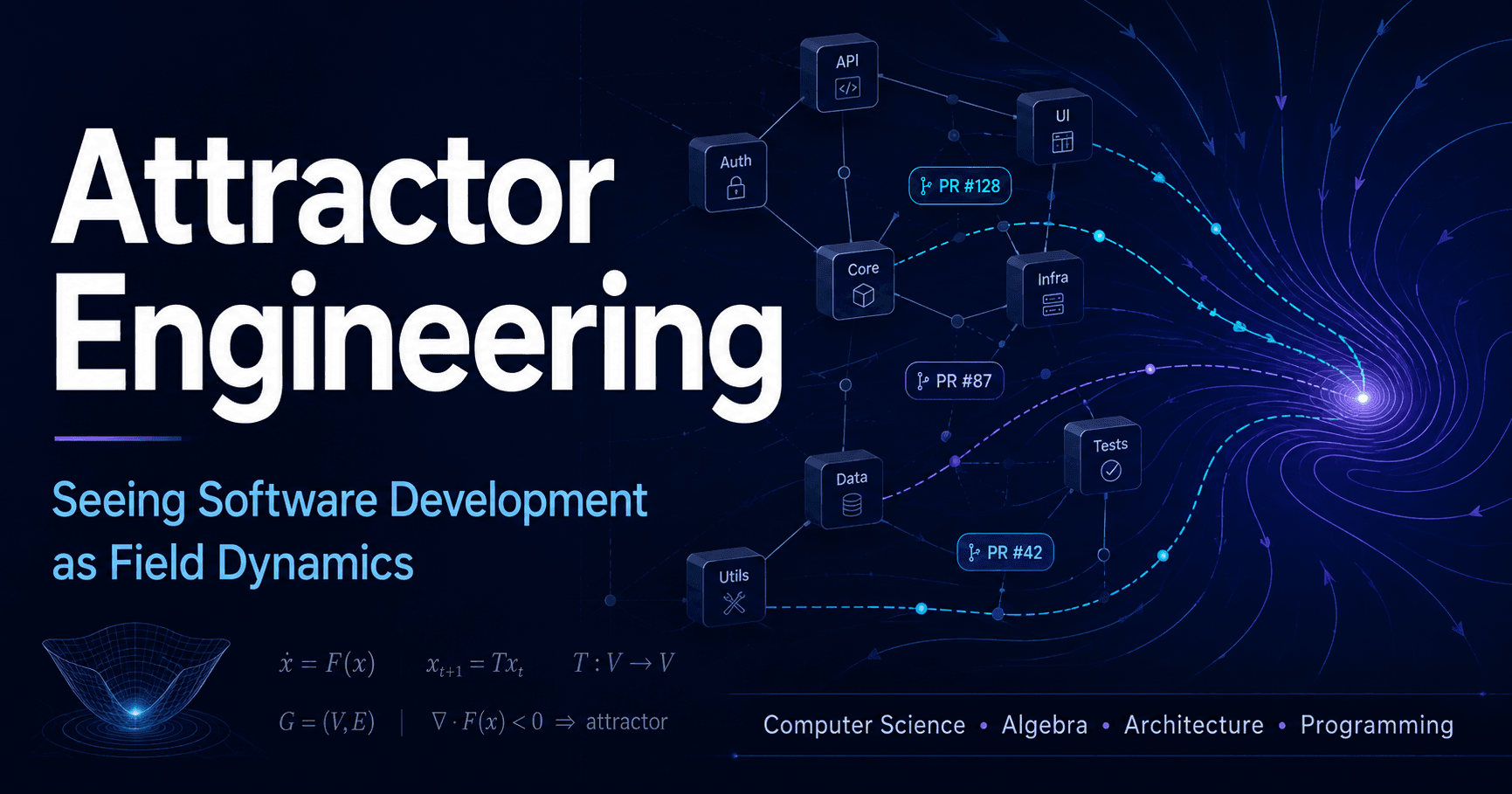
Gotanda Style as attractor engineering
Another way to describe Gotanda Style is practical attractor engineering for a codebase.
By "attractor," I mean the structure or state that a codebase naturally drifts toward as changes accumulate.
In a codebase with clear boundaries, good types, good tests, and good examples, the next change is more likely to fit the same pattern. In a codebase with a giant common module, vague services, overly convenient helpers, and bad nearby examples, changes tend to drift in that direction.
AI coding agents amplify this dynamic.
AI does not write code in a vacuum. It reads existing code, neighboring files, names, tests, previous implementations, and docs. The whole codebase becomes part of the prompt.
If the codebase contains bad local grammar, AI will often reproduce it as the natural answer. When development speeds up, the drift toward bad attractors can speed up too.
Attractor engineering means shaping where future changes are likely to land.
Gotanda Style uses the pheromone field to observe signals like:
Which files or endpoints accumulate production errors
Where performance regressions show up
Where tests are missing or boundaries are weakening
Which locations are repeatedly flagged by multiple workers
Which candidates were previously marked won't-fix
Where positive and negative signals are in conflict
This is more than alert aggregation.
It is a way to observe where the codebase is drifting, identify areas that are becoming bad basins, and use issues and repair PRs to change the trajectory.
codebase field
-> AI / human PR force
-> pheromone observation
-> issue / repair PR
-> updated codebase field
In that sense, Gotanda Style is not a system for making AI write more code.
It is an operating model for directing AI's increased change velocity toward a codebase that remains maintainable and observable.
A mathematical view
Intuitively, the pheromone field is a set of weighted signals per (scope, location).
More formally, each worker deposits a signed weight at (worker, scope, location), and the system aggregates those weights by (scope, location).
Positive weights attract attention. Negative weights inhibit attention.
Over time, each weight decays exponentially:
current = strength * 0.5 ^ (elapsed / half_life)
A simple sum can hide conflicts because positive and negative signals cancel each other out.
So the system keeps positive mass, negative mass, total variation, and conflict ratio:
net = positive - negative
total_variation = positive + negative
conflict_ratio = 1 - abs(net) / total_variation
These additional values let the system distinguish a quiet location from a contested one.
Conclusion
In LLM multi-agent systems, coordination is one of the core design problems.
Conversation-based coordination is easy to understand, but as the number of agents, the size of the codebase, and the duration of operations grow, communication and context-management costs become significant.
Gotanda Style avoids direct agent-to-agent conversation.
Instead, each agent deposits pheromones into a shared environment. Other agents read those pheromones, integrate them with evidence, create issues, and turn only the safe, automatable ones into pull requests.
The pattern has several advantages:
It is easier to add more agents.
It supports efficient exploration of large codebases.
It reduces inter-agent communication and token usage.
It works asynchronously.
It handles noise through time decay.
It can detect hotspots and conflicts that are hard to see in direct conversation.
We think this can become a useful design pattern for LLM-based software maintenance.
And for us, it is not a future idea. It is already running on a Python repository with about 200,000 lines of code, closing the loop from Sentry alert to improvement pull request.
If AI coding agents increase development velocity, maintenance has to become stronger at the same time. We need agents that observe the codebase, detect anomalies, combine improvement signals, create issues at safe granularity, and turn those issues into pull requests.
As more agents continuously observe, maintain, and improve codebases, coordination models that do not depend on constant conversation will matter more.
Gotanda Style is one experiment in that direction.