Software Architecture as a Field: Asking Better Questions About Software Evolution

AI coding agents are making us faster at writing code. That is a major shift.
But writing code faster is not the same as helping software evolve in a healthy way. The faster we stack up changes, the more important it becomes to ask what each change leaves behind in the codebase, and how it changes what can be changed next.
Traditional tooling usually looks at things that have already happened. Code state, PR diffs, test results, static dependencies, and runtime errors are all important objects of observation.
But in an era where AI coding agents can generate pull requests one after another, we need to ask one step further.
What kinds of changes does this change make possible next?
What kinds of pull requests does this PRD make more likely?
What kinds of shortcuts does this review rule make expensive?
What observation axes should this incident leave behind?
At that point, we are no longer interested only in the current state of software. We also want to reason about software evolution itself.
In this article, I introduce AAT, or Algebraic Architecture Theory, and SFT, or Software Field Theory, as theories for asking questions about software evolution. I will start by drawing a rough map of how AAT/SFT tries to look at software that keeps changing.
Software Keeps Changing
Software is not something that is completed and then slowly decays. It connects to the real world through use, and as that real world changes, the software continually drifts out of alignment.
Users, business processes, organizations, operations, regulations, libraries, and infrastructure all keep changing. Today, AI coding agents are also changing the development flow itself.
This view is not new. Lehman's laws of software evolution formalized the view that software connected to real-world problems, often called E-type software, requires continual adaptation as long as it is used. They also observed that evolving software tends to become more complex unless explicit work is done to control that complexity. And the process of evolution should not be seen as a mere sequence of changes, but as a multi-layered, multi-loop, multi-actor feedback system.
The important point here is not to jump immediately to a prescription. The answer is not simply "so we should refactor," or "so we should strengthen design review," or "so we should control AI more strictly."
The question after Lehman is a little deeper:
If software keeps changing,
what can we ask about that change?
AAT/SFT starts from this question.
Decomposing the Question of "Good Design"
In design discussions, we often encounter questions like these:
Is this design good?
Is this change safe?
Should we accept this PR?
Is this AI agent's proposal risky?
Should we still repair this system, or should we migrate?
All of these are natural questions. But as they stand, they are too large.
What does "good" mean we are preserving?
What range of future changes does "safe" refer to?
On which observation axis, and through which kind of failure, is something "risky"?
When we say "we should migrate," which change paths are we closing, and which ones are we opening?
In AAT/SFT, we break the question down a little further.
What object are we cutting out for analysis?
What do we want to preserve?
Which invariant failed?
How is that failure observed?
What kinds of changes does this change make more natural next?
This is not about turning design review into a checklist. It is about taking the judgments we already make implicitly in practice and reframing them as theoretical objects, so we can reason about changing software.
AAT (Algebraic Architecture Theory): Reading Changes Locally
AAT is a theory for reading software architecture locally.
Here, architecture is not treated as the entire codebase all at once. First, we cut out the object needed to answer the question at hand, and call it an ArchitectureObject.
We do not have to handle a huge codebase all at once. We can focus on one boundary, one dependency relation, one runtime interaction, or one semantic contract. What matters is making explicit what we chose as the object.
Next, for that object, we ask which property we want to preserve. This is called an Invariant.
What do we want to preserve? Dependency direction? A boundary? An abstraction? Substitutability? Runtime protection? Consistency of state transitions?
The phrase "good design" mixes together many such invariants. AAT separates them so that we can inspect them one by one.
If a property we wanted to preserve fails, we need evidence explaining that failure. This is called an Obstruction.
An obstruction is not just an error. It is structural evidence, a witness, showing why the property does not hold. Hidden dependencies, boundary crossings, abstraction leaks, mismatched operation orders that ought to commute, and runtime exposure can all be read as obstructions.
Finally, instead of collapsing those observations into a single score, we read them across multiple axes. This is the role of ArchitectureSignature.
In short, the AAT way of reading looks like this:
Which object is this change operating on?
Which invariant do we want to preserve?
Which obstruction has appeared?
On which signature axis does it appear?
Within what boundary can we make that claim?
AAT does not reduce "architectural quality" to a single number. It decomposes design judgment into object, preserved property, violation, observation axis, and boundary.
What Does It Mean to See Architecture Algebraically?
Why call this algebraic?
In AAT, we do not only look at architecture as a static diagram. We treat it as an object that can be operated on. There is an architecture object, and there are operations such as split, replace, abstract, protect, migrate, and repair. We ask what those operations preserve, what they fail to preserve, and how they compose with other operations.
The object of interest has this shape:
object
+ operation
+ preservation
+ obstruction
+ composition
AAT is not merely evaluation. There is an object, there are operations, there is structure that is preserved, there are obstructions where preservation fails, and there are sequences of operations. To study that structure, AAT treats architecture algebraically.
For example, one change may preserve dependency direction. Another change may preserve an abstraction boundary.
If we apply those two changes in sequence, does their preservation compose?
Does an obstruction appear in the middle?
If two change paths appear to reach the same result, do they have the same signature trajectory?
This is the kind of structure AAT wants to study.
What Do Design Principles Preserve?
From this point of view, familiar design principles in software engineering look a little different.
For example, SOLID is not an all-purpose design principle in AAT. It is better read mainly as a family of principles for preserving local contracts.
SRP tries to preserve responsibility boundaries.
OCP asks for extension without breaking existing contracts.
LSP asks that an abstraction be observable in the same way regardless of which concrete implementation is substituted.
ISP tries to separate unnecessary dependencies from interfaces.
DIP tries to map dependencies on concrete details into dependencies on abstractions.
What SOLID mainly deals with are invariants such as local contracts, abstractions, substitutability, and interface separation.
Layered Architecture deals with a different layer. What Layered Architecture tries to preserve is not so much the responsibility of each individual class, but the dependency direction of the whole system.
Is there a ranking between upper and lower layers, and do dependencies follow that direction?
Are there dependencies that skip across layers?
Are cycles being introduced?
Is the system kept in a decomposable form?
In AAT terms, SOLID mainly handles invariants in the local contract layer, while Layered Architecture handles invariants in the global structure layer.
SOLID
-> local contract / abstraction / substitutability
Layered Architecture
-> dependency direction / ranking / acyclicity / decomposability
The advantage of this classification is that we do not have to treat design principles as competing single answers.
A system can follow SOLID and still fail to decompose cleanly as a whole. Conversely, Layered Architecture can be preserved while individual abstractions fail to be substitutable.
If the invariants they preserve are different, then their failure modes are different, and the signature axes we should observe are different as well.
For Clean Architecture, we look at boundary preservation, inward dependencies, and abstraction consistency.
For Event Sourcing, we look at replay, projection, and the relation between history and current state.
For Circuit Breaker, we look at runtime protection and failure locality.
AAT does not rank design principles by asking which one is correct. It classifies which invariant family each principle carries, which obstructions it prevents, and which signature axes it appears on.
The Architecture Zero-Curvature Theorem: Connecting Good Design to Measurement
AAT takes this idea one step further and expresses it using the vocabulary of curvature.
Here, curvature means the obstruction that remains relative to a selected invariant. If there is a structure we want to preserve, and a witness that violates that structure remains, then there is curvature.
Intuitively, we can read it this way:
There is curvature
= somewhere, the structure we wanted to preserve is violated
Curvature is zero
= within the selected scope, no required obstruction witness remains
Up to this point, this is almost definitional. The important part comes next.
AAT is not trying to restate "good design is design without violations." Here, a law should be read as an explicit rule describing a property we want to preserve. The goal is to connect lawfulness with respect to selected laws to finitely observable obstruction witnesses and to the required axes of an ArchitectureSignature being zero.
lawfulness for the selected laws
<-> no required obstruction witness
<-> required signature axes are zero
AAT calls this connection the Architecture Zero-Curvature Theorem.
The point is that three layers become connected.
semantics:
lawful under the selected law universe
witness:
no required obstruction is finitely detected
measurement:
required signature axes are observed as zero
In ordinary design reviews, phrases such as "the boundary is preserved," "responsibilities are separated," or "this is easy to extend" are often used ambiguously. The zero-curvature theorem offers a bridge: relative to which law, which witness, which observation, and which signature are we making that judgment?
Good design in AAT is not merely design that looks elegant. It is design where, within the selected laws, required obstruction witnesses are absent, and this can also be observed as zero on the signature axes.
The value of the theorem is not the slogan "if there are no violations, it is good." Its value is that it lets us move a design judgment between semantics, witnesses, and measurable signature axes.
SFT (Software Field Theory): Making Software Evolution Computable
If AAT asks, "What did this change preserve, and what did it fail to preserve?", SFT goes one step further and asks, "What kinds of changes does this change make more natural next?" On top of the local algebra built by AAT, SFT builds a framework for reasoning about software evolution.
AAT looks at the local structure of one change. It asks which object the change operates on, what it preserved, where obstructions remain, what can be said on which observation axes, and where those claims stop.
SFT looks at the field in which that change is placed. It asks how the change guides the next changes, which paths it makes cheaper, which paths it makes harder to see, which feedback remains as memory, and which futures become reachable.
In SFT, this whole context is called a field.
A field is not only the codebase. It includes requirements, design documents, PRDs, issues, review rules, CI, type checkers, runtime feedback, AI agent policies, and everything else that acts on the codebase. It determines which changes look natural, which changes become difficult, what becomes observable, and which feedback remains for the next judgment.
field
= codebase
+ artifacts
+ practices
+ agents
+ governance
+ feedback
SFT is not a theory of the codebase alone. It is a theory of the whole development organization that writes requirements, designs systems, creates issues, opens PRs, reviews them, runs CI, and receives operational feedback.
Then what is a force?
In this article, I use force for the bundle of candidate updates that artifacts such as PRDs, specs, issues, AI proposals, and incident reports create in the field. A single PRD does not determine exactly one PR. But that PRD changes which issue decomposition feels natural, which PRs are likely to be created, and which architecture regions are likely to be touched.
force
= candidate updates that an artifact gives to the field
= changes in operation support / observation boundary / selection policy
Here, operation support means which operations are possible, natural, and low-cost. Observation boundary means what is visible and what is not. Selection policy means which choices are likely to pass through the process.
The field is the state. Force is artifact-mediated change. Future is the range of paths reachable from that field.
Even if two codebases have the same module graph, their next natural changes can differ if their fields differ. Past incidents, old workarounds, implicit ownership boundaries, and local patterns that an AI agent can easily mimic all change future operation support and selection policy.
What Does "Computation" Mean in SFT?
Computable here does not mean that we can predict the future of software as one exact outcome. It means that, under an explicit field model, operation support, observation boundary, and horizon, we can treat the range of reachable futures as a bounded problem.
For example, when an artifact enters a field, SFT views questions like the following as computational problems.
input:
current field
+ artifact
+ operation support
+ observation axes
+ horizon
output:
reachable path classes
+ affected architecture regions
+ changed signature axes
+ obstruction witness candidates
+ missing invariants / boundaries
+ review / CI recommendations
On the theoretical side, this set of reachable paths is called a ForecastCone. On the practical side, the readable report summarizing it is called a ConsequenceEnvelope.
The important point is that SFT does not claim, "this PRD will necessarily produce this PR." What SFT wants to see is which paths become closer in this field, which paths become farther away, and which obstructions become visible.
PRDs Shape Future PRs
The intuition of SFT is easier to grasp if we look at the flow from PRD to PR.
A PRD is not merely a requirements document. It is an artifact that partially shapes the form of future pull requests. Even for the same request, "add this feature," the PRs that become likely differ depending on whether the PRD states boundaries, responsibilities, and properties that should be observed. And in many cases, PRDs are written by people who do not directly write code, such as product managers, designers, and domain experts. Non-engineers also apply force to the codebase through artifacts.
PRD
-> possible issue decomposition
-> possible PR shapes
-> possible architecture changes
-> possible signature changes
In SFT, we ask what force this PRD applies to the codebase and what kind of ForecastCone it opens. But that cone does not represent one predetermined future. It is closer to the cone of uncertainty in a weather forecast: it represents the range of futures that may become reachable.
What kinds of PRs are likely to emerge from this PRD?
Which architecture regions are those PRs likely to affect?
Which invariants might they preserve, and which obstructions might they create?
Within the
ForecastCone, which future paths become closer and which become farther away?
For this reason, SFT asks questions in the following form:
Which
ForecastConeopens in this field?Which paths become natural, and which paths move farther away?
What is observable, and what remains unobserved?
In this sense, SFT is a theory that tries to treat software evolution as a computable object.
Conway's Law: Systems Reflect Organizational Communication Structures
Conway's Law can be read naturally in the vocabulary of SFT. As is well known, Conway's Law is usually described as the empirical rule that the design of a system reflects the communication structure of the organization that built it.
In SFT, we read this not merely as a metaphor, but as a phenomenon where an organization field shapes the architecture future.
The organizational structure does not directly command the codebase to have a particular architecture. But team boundaries, ownership, review routes, approval flows, on-call boundaries, and issue decomposition all change which modifications look natural, which PRs are low-cost, and which changes are likely to pass review.
organization structure
-> communication paths
-> ownership boundaries
-> issue decomposition
-> PR shape
-> operation support
-> architecture future
Organizational structure changes operation support, and operation support changes day-to-day design changes. Through repetition, that pattern settles into the codebase as architecture.
For example, if an organization is split into Frontend Team, Backend Team, Data Team, and Infra Team, issues and PRs are likely to follow those boundaries. As a result, the architecture is also likely to split along those boundaries. On the other hand, if the organization is structured around product capabilities such as Search, Checkout, and Billing, changes that preserve those capability boundaries become more natural.
In SFT terms, Conway's Law can be read as follows:
organization field
-> recurrent PR shape
-> recurrent architecture operation
-> architecture structure
If we want a desirable architecture to become a natural future, we need to design the organization field so that changes preserving that architecture are low-cost and repeatable.
Conway's Law is not a story about system structure accidentally resembling organization structure. It is a story about organizations shaping the ease of day-to-day changes, and the repetition of those changes settling into architecture.
ArchSig: A Lens for Observation
To connect AAT/SFT to real development, we need an observation layer. ArchSig is the concept for that layer.
AAT turns architecture into a local algebra.
ArchSig makes architecture observable.
SFT makes software evolution computable.
ArchSig is a lens for reading artifacts such as codebases, PRs, issues, reviews, and incident traces. It asks which signature axes changed, which obstructions appeared, and what becomes input to the next field update.
I plan to discuss ArchSig in a separate article. For now, I only want to emphasize that AAT/SFT is meant to connect to observation and tooling.
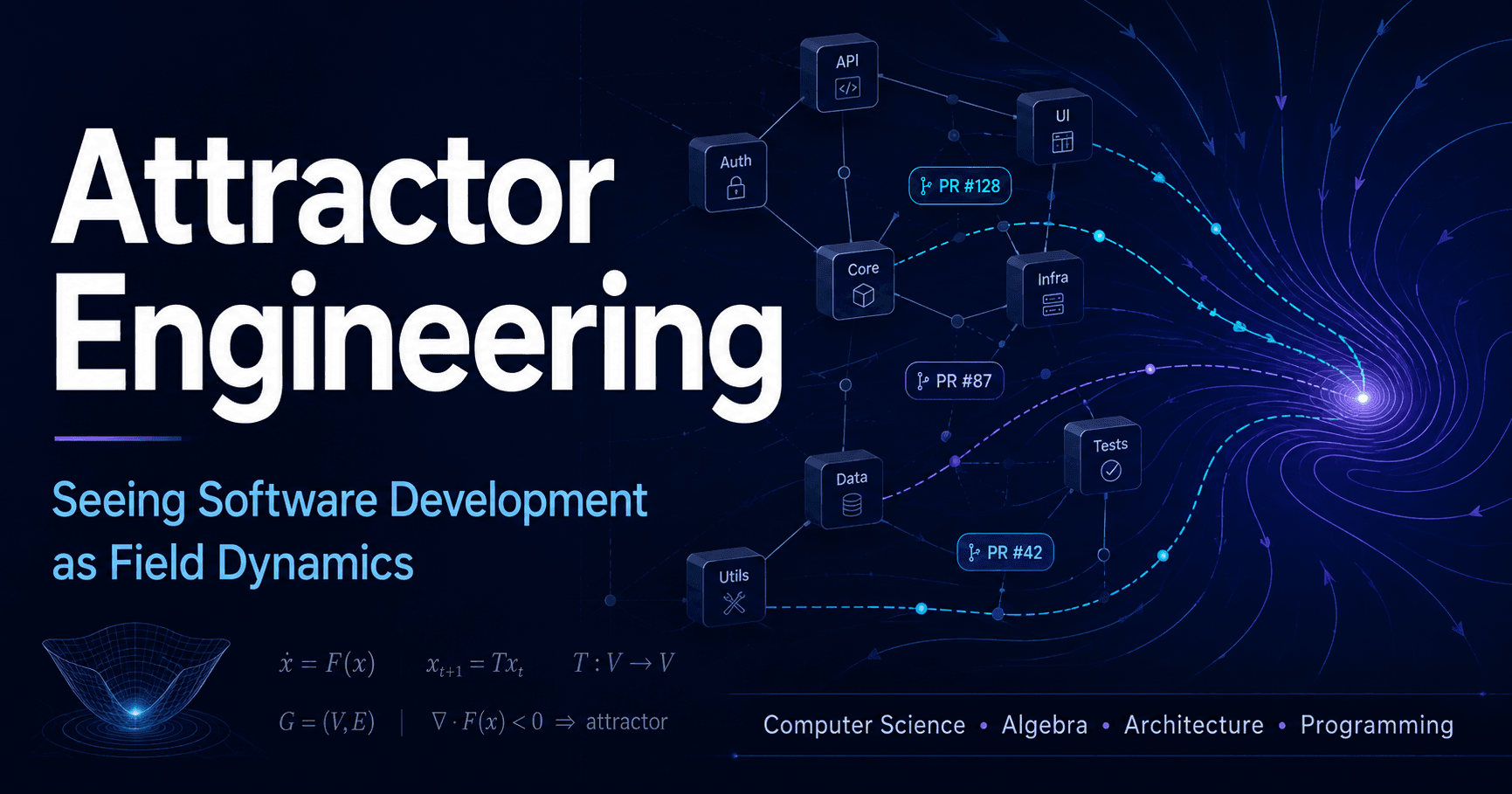
Attractor Engineering: Designing Fields Where Good Changes Become Natural
One especially important idea in SFT is attractor engineering.
Here, an attractor is a direction of change that becomes repeatedly likely within a field. Good design decisions, good abstractions, good tests, good review rules, and good PRDs make it easier for the next good change to follow. Conversely, easy shortcuts, ambiguous responsibilities, broken boundaries, and invisible runtime coupling make the next easy shortcut more likely.
A codebase has a bias in how it is likely to be changed next. SFT treats that bias as a property of the field.
Attractor engineering means designing that bias.
Arrange the field so that good changes are:
easy to find,
easy to write,
easy to review,
protected by CI,
and updated by operational feedback.
This is somewhat different from the idea of simply placing strong restrictions on AI agents. Of course, prohibitions and guardrails are necessary. But by themselves, they only keep piling rules on top of an undesirable field.
The goal of attractor engineering is to build a field where good paths are naturally selected, and bad shortcuts are expensive, observable, and detectable in review.
This becomes even more important in the age of AI coding agents. AI agents tend to choose the path that looks most natural from the existing codebase and surrounding artifacts. In this sense, a codebase is not only an implementation; it is also a prompt for AI agents. If the field is undesirable, AI agents can amplify bad local patterns quickly. If the field is well designed, AI agents can also amplify good structure quickly.
In SFT terms, attractor engineering means designing future operation support.
Which changes look natural?
Which changes become low-cost?
Which violations become observable?
Which feedback remains in the next field?
This question is not merely quality control. It is the design of the direction of software evolution.
What AAT/SFT Is Trying to Do
AAT/SFT is trying to do three main things.
The first is to change the question.
Is this design good?
Instead of trying to answer that question as-is, we decompose it:
What object are we talking about?
What do we want to preserve?
Which invariant failed?
What are we failing to observe?
What kinds of changes does this change make more natural next?
This is not meant to make practical design judgment lighter. It is meant to make implicit judgment more tractable.
The second is to formalize the core of the theory in the Lean theorem prover.
We do not need to formalize all of AAT/SFT at once. The first step is to make the foundations of AAT, such as local algebra, invariants, obstructions, signatures, and the zero-curvature theorem, verifiable in Lean.
architecture object
+ operation
+ invariant
+ obstruction
+ signature
+ theorem boundary
Once this core is formalized, we can mechanically check what follows from which assumptions, and where the consequences stop.
The third is to connect the theory to practical tools and methods.
AAT reads design judgment in terms of invariants and obstructions. ArchSig makes those observable from codebases, PRs, issues, reviews, and incident traces. SFT uses those observations to reason about which ForecastCone opens and which paths become natural.
AAT
-> theoretical core
Lean
-> formalization of the core
ArchSig / tooling
-> observation of real artifacts
SFT
-> computation of software evolution
The eventual goal is to have tools for observing, questioning, and improving requirements, design, issues, PRs, review, CI, operational feedback, and the behavior of AI agents on top of the same theory.
Closing
Lehman saw that software keeps changing. Software connected to the real world continues to drift from its environment as long as it is used. It is changed to close that gap, and through being changed, it gains complexity and creates new feedback loops.
AAT/SFT sits on the same line of concern.
AAT asks about the local structure of that change. What object are we looking at, what do we preserve, which invariant failed, and on which axes can we observe it?
SFT asks how that change shapes the next change. It asks which futures are pulled closer, and which futures are pushed farther away, by requirements, design, issues, PRs, review, CI, operational feedback, and AI agents.
A good theory does not necessarily give all the answers immediately. But it gives us better questions, and it tells us how far those questions can be answered.
As Lehman showed, software keeps changing. If so, we should not merely accept that change. We should make it something we can ask about.
AAT/SFT is an attempt to define questions for software that keeps changing.
Further Reading
If you want to read more about the mathematical definitions of AAT/SFT, theorem boundaries, and the connection to SFT, see the following primary documents:
For a practical example of attractor engineering, and as an example of a multi-agent system for automatically maintaining a codebase, you may also want to read the article on Gotanda Style: